Aprendizaje Federado con Flower: Construyendo Modelos de IA Colaborativos y Preservadores de la Privacidad
1. Contexto del Problema: La Privacidad de Datos en la Era de la IA Distribuida
En el panorama actual de la Inteligencia Artificial y el Machine Learning, la disponibilidad de grandes volúmenes de datos es crucial para entrenar modelos robustos y precisos. Sin embargo, cada vez más, estos datos residen en silos distribuidos, en dispositivos de usuario, en diferentes organizaciones o en ubicaciones geográficas diversas. La centralización de estos datos para el entrenamiento de modelos plantea desafíos significativos en términos de privacidad, seguridad, cumplimiento normativo (como GDPR o HIPAA) y costos de comunicación. [2, 5, 21]
El enfoque tradicional de Machine Learning, donde todos los datos se recopilan en un servidor central para el entrenamiento, se vuelve insostenible cuando la información es sensible o cuando el volumen de datos es tan masivo que su transferencia es inviable. Esto ha impulsado la necesidad de paradigmas de entrenamiento que permitan a los modelos aprender de datos distribuidos sin que estos datos abandonen su origen. Aquí es donde el Aprendizaje Federado (FL) emerge como una solución transformadora. [2, 5, 17, 21]
2. Fundamento Teórico: ¿Qué es el Aprendizaje Federado?
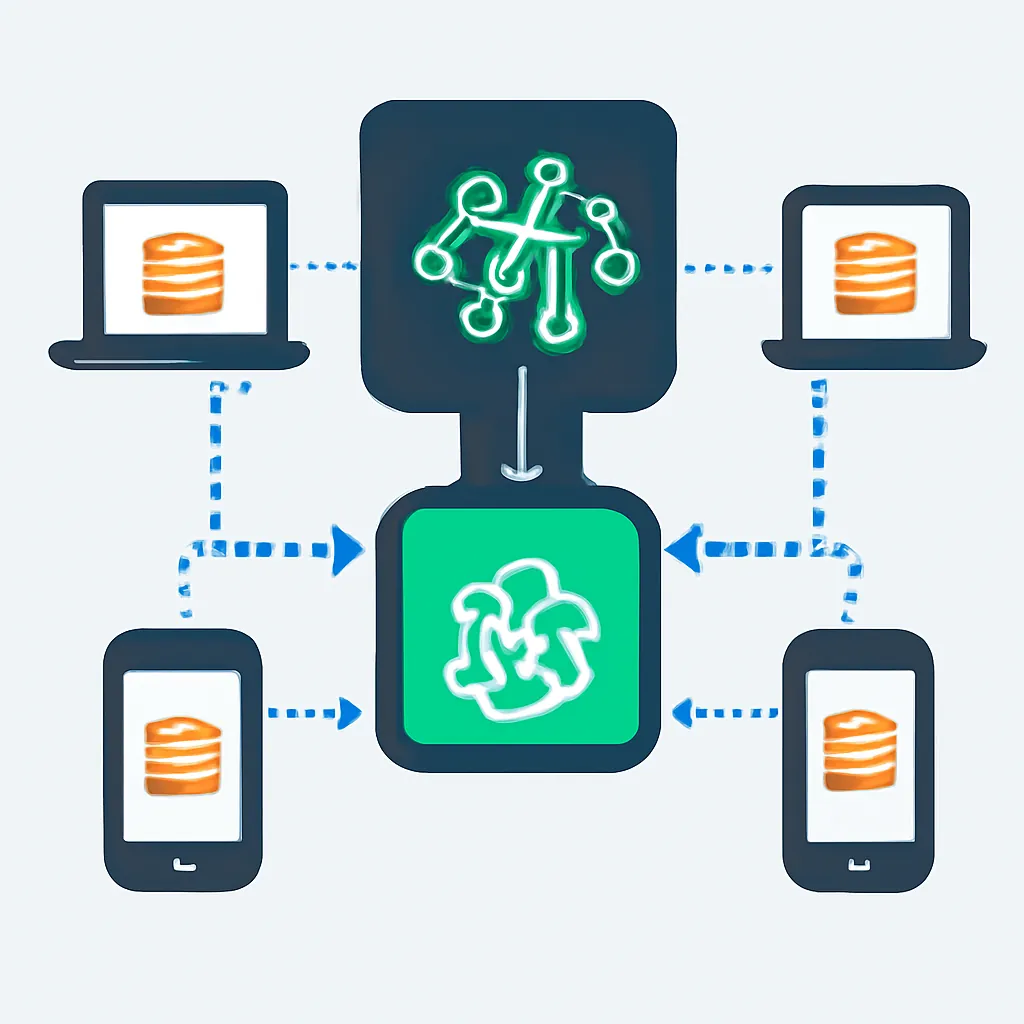
El Aprendizaje Federado es una técnica de Machine Learning que permite entrenar un algoritmo a través de una arquitectura descentralizada compuesta por múltiples dispositivos o servidores, cada uno conteniendo sus propios datos locales y privados, sin intercambiar los datos en sí. [2, 7, 17, 19]
El principio central del FL es llevar el modelo a los datos, en lugar de llevar los datos al modelo. En lugar de agrupar los datos en un servidor central, un modelo global se envía a los dispositivos locales. Cada dispositivo entrena el modelo con sus propios datos, y solo las actualizaciones del modelo (por ejemplo, los pesos o gradientes) se envían de vuelta a un servidor central. El servidor agrega estas actualizaciones de múltiples clientes para mejorar el modelo global, que luego se distribuye de nuevo a los clientes en una ronda iterativa. [2, 5, 7, 19]
2.1. Principios Clave
- Privacidad por Diseño: Los datos brutos nunca abandonan el dispositivo o la ubicación local, lo que garantiza la confidencialidad y seguridad. [2, 19, 20]
- Descentralización: El entrenamiento ocurre en el borde de la red, reduciendo la dependencia de un servidor central para el almacenamiento de datos masivos. [2, 6]
- Colaboración: Múltiples entidades pueden contribuir al entrenamiento de un modelo común sin revelar sus datos privados. [21]
2.2. Tipos de Aprendizaje Federado
- Aprendizaje Federado Horizontal (Federated Averaging - FedAvg): Es el tipo más común. Se aplica cuando los conjuntos de datos de diferentes clientes comparten las mismas características (columnas) pero difieren en las muestras (filas). Por ejemplo, diferentes hospitales que tienen datos de pacientes con las mismas características, pero de pacientes distintos. [7]
- Aprendizaje Federado Vertical: Se utiliza cuando los conjuntos de datos de diferentes clientes comparten las mismas muestras (filas) pero difieren en las características (columnas). Por ejemplo, un banco y una empresa de comercio electrónico que tienen datos sobre los mismos clientes, pero con diferentes atributos.
- Aprendizaje Federado por Transferencia: Combina el aprendizaje federado con el aprendizaje por transferencia, donde un modelo pre-entrenado se adapta a nuevos datos locales.
2.3. Promediado Federado (FedAvg)
El algoritmo de Promediado Federado (FedAvg) es la base de la mayoría de las implementaciones de FL. Funciona de la siguiente manera: [7]
- El servidor inicializa un modelo global y lo envía a un subconjunto de clientes seleccionados.
- Cada cliente descarga el modelo, lo entrena localmente utilizando sus propios datos privados durante varias épocas.
- Los clientes envían las actualizaciones de los pesos (o gradientes) del modelo de vuelta al servidor.
- El servidor agrega las actualizaciones de todos los clientes participantes (generalmente promediando los pesos) para crear un nuevo modelo global mejorado.
- Este proceso se repite durante un número predefinido de rondas hasta que el modelo converge.
3. Implementación Práctica: Aprendizaje Federado con Flower
Flower es un framework de código abierto para la IA colaborativa y la ciencia de datos, diseñado para simplificar la implementación de sistemas de Aprendizaje Federado. Es agnóstico al framework de ML subyacente (funciona con PyTorch, TensorFlow, JAX, etc.) y permite construir sistemas FL con numerosos clientes conectados. [3, 9]
3.1. Configuración del Entorno
Primero, necesitamos instalar Flower y las dependencias necesarias. Para este ejemplo, usaremos PyTorch.
pip install -q flwr[simulation] torch torchvision matplotlib
3.2. Definición del Modelo y Carga de Datos
Vamos a usar un modelo simple de clasificación de imágenes (una CNN) y el conjunto de datos CIFAR-10 para demostrar el FL. En un escenario real, cada cliente tendría una porción diferente del conjunto de datos.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from collections import OrderedDict
from typing import List, Tuple
import flwr as fl
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 1. Definir el modelo (una CNN simple)
class Net(nn.Module):
def __init__(self) -> None:
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 2. Cargar y transformar el conjunto de datos CIFAR-10
def load_data(partition_id: int, num_partitions: int):
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
trainset = datasets.CIFAR10('./data', train=True, download=True, transform=transform)
testset = datasets.CIFAR10('./data', train=False, download=True, transform=transform)
# Simular particiones de datos para clientes federados
# En un escenario real, cada cliente ya tendría sus propios datos
train_size = len(trainset) // num_partitions
test_size = len(testset) // num_partitions
train_indices = list(range(partition_id * train_size, (partition_id + 1) * train_size))
test_indices = list(range(partition_id * test_size, (partition_id + 1) * test_size))
trainloader = DataLoader(torch.utils.data.Subset(trainset, train_indices), batch_size=32, shuffle=True)
testloader = DataLoader(torch.utils.data.Subset(testset, test_indices), batch_size=32)
return trainloader, testloader
# 3. Funciones de entrenamiento y evaluación locales
def train(net: nn.Module, trainloader: DataLoader, epochs: int):
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for _ in range(epochs):
for images, labels in trainloader:
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
def test(net: nn.Module, testloader: DataLoader):
criterion = nn.CrossEntropyLoss()
correct, total, loss = 0, 0, 0.0
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(DEVICE), labels.to(DEVICE)
outputs = net(images)
loss += criterion(outputs, labels).item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return loss / len(testloader), correct / total
3.3. Implementación del Cliente Federado
Un cliente Flower es una clase que implementa la interfaz flwr.client.Client o flwr.client.NumPyClient. Define cómo el cliente interactúa con el servidor: cómo recibe el modelo, lo entrena y envía las actualizaciones.
class CifarClient(fl.client.NumPyClient):
def __init__(self, cid: int, num_partitions: int):
self.cid = cid
self.net = Net().to(DEVICE)
self.trainloader, self.testloader = load_data(cid, num_partitions)
def get_parameters(self, config) -> List[np.ndarray]:
return [val.cpu().numpy() for _, val in self.net.state_dict().items()]
def set_parameters(self, parameters: List[np.ndarray]):
params_dict = zip(self.net.state_dict().keys(), parameters)
state_dict = OrderedDict({k: torch.tensor(v) for k, v in params_dict})
self.net.load_state_dict(state_dict, strict=True)
def fit(self, parameters: List[np.ndarray], config) -> Tuple[List[np.ndarray], int, dict]:
self.set_parameters(parameters)
train(self.net, self.trainloader, epochs=1)
return self.get_parameters(config={}), len(self.trainloader.dataset), {}
def evaluate(self, parameters: List[np.ndarray], config) -> Tuple[float, int, dict]:
self.set_parameters(parameters)
loss, accuracy = test(self.net, self.testloader)
return loss, len(self.testloader.dataset), {"accuracy": accuracy}
def client_fn(cid: str) -> CifarClient:
return CifarClient(int(cid), num_partitions=10) # Asumimos 10 clientes para la simulación
3.4. Implementación del Servidor Federado
El servidor Flower orquesta el proceso de entrenamiento federado. Define la estrategia de agregación (por ejemplo, FedAvg) y cómo se seleccionan los clientes.
# 4. Definir la estrategia de agregación del servidor
strategy = fl.server.strategy.FedAvg(
fraction_fit=0.5, # Fracción de clientes a entrenar en cada ronda
fraction_evaluate=0.5, # Fracción de clientes a evaluar en cada ronda
min_fit_clients=2, # Mínimo de clientes para entrenar
min_evaluate_clients=2, # Mínimo de clientes para evaluar
min_available_clients=10, # Mínimo de clientes disponibles para iniciar una ronda
evaluate_metrics_aggregation_fn=lambda metrics: {"accuracy": sum([m["accuracy"] * n for m, n in metrics]) / sum([n for _, n in metrics])},
)
# 5. Iniciar la simulación del Aprendizaje Federado
# En un entorno de producción, los clientes se conectarían de forma independiente
num_clients = 10
# Crear un diccionario de clientes para la simulación
clients = {str(i): client_fn(str(i)) for i in range(num_clients)}
# Iniciar la simulación
history = fl.simulation.start_simulation(
client_fn=client_fn,
num_clients=num_clients,
config=fl.server.ServerConfig(num_rounds=5), # Número de rondas de entrenamiento
strategy=strategy,
)
print("Historial de entrenamiento:", history.metrics_centralized)
Este código simula un entorno de Aprendizaje Federado donde 10 clientes entrenan un modelo de clasificación de imágenes de forma colaborativa. El servidor agrega los modelos locales en cada ronda, y el modelo global mejora iterativamente sin que los datos de entrenamiento individuales de cada cliente salgan de su "dispositivo" simulado. [3, 12, 13, 15]
4. Aplicaciones Reales: Donde el Aprendizaje Federado Brilla
El Aprendizaje Federado no es solo un concepto teórico; ya está impulsando varias aplicaciones de uso generalizado y transformando sectores donde la sensibilidad de los datos es primordial. [2, 6]
- Dispositivos Móviles: Google utiliza FL para mejorar las sugerencias de teclado (Gboard) y el reconocimiento de voz en Android, aprendiendo de los patrones de escritura y habla de los usuarios sin enviar datos sensibles a la nube. [6, 10, 11, 23]
- Salud: Hospitales e instituciones de investigación pueden entrenar modelos compartidos para el descubrimiento de fármacos, diagnóstico de enfermedades (ej. detección de tumores en imágenes médicas) o la predicción de resultados de pacientes, manteniendo la privacidad de los registros médicos. [9, 20, 27]
- Finanzas: Bancos y otras instituciones financieras pueden colaborar en la detección de fraudes o la evaluación de riesgos crediticios, entrenando modelos sobre datos transaccionales sin compartir información confidencial de los clientes. [9]
- Internet de las Cosas (IoT) y Ciudades Inteligentes: Sensores distribuidos pueden entrenar modelos para optimizar el tráfico, monitorear la calidad del aire o gestionar redes energéticas, aprovechando los datos locales sin comprometer la privacidad de los residentes. [1, 6, 9]
- Conducción Autónoma: Los vehículos pueden entrenar modelos de percepción y predicción de comportamiento en el propio coche, compartiendo solo las actualizaciones del modelo para mejorar un modelo global sin exponer datos de ubicación o patrones de conducción individuales. [7, 20]
- Industria 4.0: En entornos de fabricación, el FL puede optimizar procesos de producción y mantenimiento predictivo, donde los sensores de la maquinaria recopilan datos localmente, ayudando a identificar problemas de rendimiento y reducir el tiempo de inactividad. [6, 8, 20]
5. Mejores Prácticas y Desafíos
Aunque el Aprendizaje Federado ofrece ventajas significativas, su implementación en producción conlleva desafíos que deben abordarse con mejores prácticas:
- Heterogeneidad de Datos (Non-IID Data): Los datos en los dispositivos de los clientes a menudo no están distribuidos de forma idéntica e independiente (Non-IID), lo que puede afectar la convergencia y el rendimiento del modelo global. Estrategias como la personalización del modelo o algoritmos de agregación más sofisticados pueden mitigar esto. [2, 7, 8]
- Costos de Comunicación: La comunicación entre el servidor y los clientes puede ser un cuello de botella, especialmente con un gran número de clientes o modelos grandes. Técnicas como la compresión de modelos, la cuantización o la selección inteligente de clientes pueden reducir la carga. [2]
- Seguridad y Privacidad Avanzada: Aunque el FL protege la privacidad de los datos brutos, las actualizaciones del modelo aún pueden contener información sensible. Técnicas como la Privacidad Diferencial (Differential Privacy) añaden ruido a las actualizaciones para proteger aún más la privacidad, y la Computación Multipartita Segura (Secure Multi-Party Computation - SMPC) permite la agregación de actualizaciones cifradas. [5]
- Escalabilidad y Robustez: Gestionar un gran número de clientes, algunos de los cuales pueden ser poco fiables o tener recursos limitados, requiere una infraestructura robusta y estrategias de tolerancia a fallos.
- Sesgo y Equidad: La agregación de modelos de clientes con distribuciones de datos sesgadas puede llevar a un modelo global sesgado. Es crucial monitorear y aplicar técnicas de equidad para asegurar que el modelo funcione bien para todos los grupos de usuarios. [1]
6. Aprendizaje Futuro y Recursos Adicionales
El Aprendizaje Federado es un campo de investigación activo y en rápida evolución. Para profundizar, considera explorar los siguientes temas y recursos:
- Otros Frameworks: Además de Flower, TensorFlow Federated (TFF) de Google es otro framework robusto para FL, especialmente para usuarios de TensorFlow. PySyft de OpenMined se enfoca en la privacidad y la computación segura. [2, 10, 11, 14, 19, 22]
- Privacidad Diferencial y Cifrado Homomórfico: Investiga cómo estas técnicas criptográficas se integran con FL para proporcionar garantías de privacidad más sólidas.
- Personalización en FL: Cómo adaptar el modelo global a las necesidades específicas de cada cliente sin perder los beneficios de la colaboración.
- Evaluación y Métricas en FL: Desafíos en la evaluación del rendimiento del modelo en un entorno distribuido y cómo definir métricas significativas.
- Investigación Actual: Sigue las publicaciones de conferencias como NeurIPS, ICML y AISTATS para estar al tanto de los últimos avances en FL.
El Aprendizaje Federado representa un cambio de paradigma fundamental en cómo construimos y desplegamos sistemas de IA, permitiendo la colaboración a escala global mientras se respeta la privacidad individual. Dominar sus principios e implementación es una habilidad invaluable para cualquier desarrollador de IA/ML que trabaje con datos sensibles o distribuidos.