Introducción a los Modelos Difusivos para Generación de Imágenes: Fundamentos y Primeros Pasos
Una guía para principiantes sobre el funcionamiento y la aplicación básica de los modelos de difusión en inteligencia artificial.
¿Qué son los Modelos Difusivos?
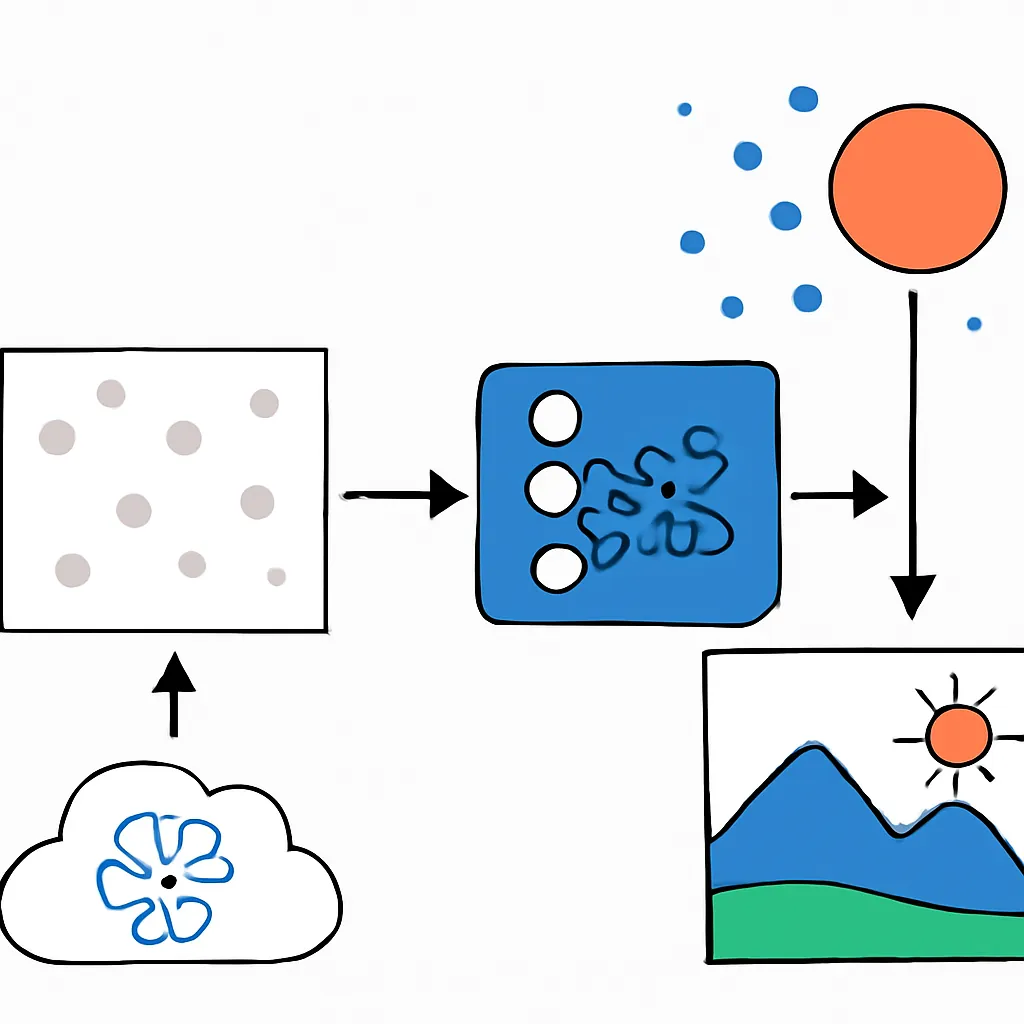
Los modelos difusivos son una clase innovadora de modelos generativos que han ganado mucha atención en el campo de la inteligencia artificial, especialmente para la generación de imágenes con alta calidad y detalle. Su funcionamiento se inspira en procesos físicos de difusión, donde ruido gaussiano es agregado y luego removido progresivamente para reconstruir datos.
A diferencia de los modelos clásicos como las Redes Generativas Antagónicas (GANs), los modelos difusivos funcionan mediante un proceso de contaminación y posterior eliminación controlada del ruido, lo que permite generar imágenes muy realistas y diversificadas.
Principios Clave de los Modelos Difusivos
- Proceso de difusión directa: Se añade ruido gaussiano a una imagen original en pasos discretos, hasta obtener una distribución prácticamente aleatoria.
- Proceso inverso de difusión: El modelo aprende a eliminar el ruido paso por paso, reconstruyendo la imagen original o generando una imagen nueva a partir del ruido.
- Función objetivo: Durante el entrenamiento, el modelo minimiza la diferencia entre el ruido real añadido y el ruido predicho por el modelo, aprendiendo a generar imágenes a partir del ruido inicial.
Arquitectura Básica y Componentes
Generalmente, los modelos difusivos emplean una red neuronal tipo U-Net para estimar el ruido durante el proceso inverso. La U-Net es capaz de captar tanto características globales como detalles finos, lo que es crucial para el éxito de la generación.
Los pasos principales son:
- Entrada: Imagen corrompida con ruido y un valor que indica el paso actual.
- Output: Estimación del ruido presente en la imagen para poder removerlo.
Ejemplo Práctico Simplificado en Python usando PyTorch
Aquí vemos una estructura básica de cómo entrenar un pequeño modelo difusivo para aprendizaje de eliminación de ruido. Este código es educativo y simplificado para ilustrar el flujo principal.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# Definición simplificada de una U-Net pequeña
class SimpleUNet(nn.Module):
def __init__(self):
super(SimpleUNet, self).__init__()
self.conv1 = nn.Conv2d(1, 64, 3, padding=1)
self.conv2 = nn.Conv2d(64, 64, 3, padding=1)
self.relu = nn.ReLU()
self.conv3 = nn.Conv2d(64, 1, 3, padding=1)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x
# Simulamos el proceso de añadir ruido gaussiano
def add_noise(x, noise_level=0.1):
noise = torch.randn_like(x) * noise_level
return x + noise, noise
# Entrenamiento básico
transform = transforms.Compose([transforms.ToTensor()])
dataset = datasets.MNIST(root='data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
model = SimpleUNet()
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.MSELoss()
for epoch in range(2): # pocas épocas para ejemplo
for imgs, _ in dataloader:
noisy_imgs, noise = add_noise(imgs, noise_level=0.2)
pred_noise = model(noisy_imgs)
loss = loss_fn(pred_noise, noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Época {epoch+1}, pérdida: {loss.item():.4f}")
En este ejemplo básico, el modelo aprende a predecir el ruido agregado para poder removerlo, que es el núcleo del entrenamiento en modelos de difusión.
Aplicaciones Prácticas y Estado del Arte
Los modelos difusivos son especialmente usados hoy en generación de imágenes creativas, desde arte digital hasta imágenes fotorrealistas para diseño, incluyendo plataformas como DALL·E 2 y Stable Diffusion. Además, tienen ventajas:
- Mayor estabilidad en el entrenamiento comparado con GANs.
- Capacidad para generar alta variedad y calidad.
- Fácil integración con condiciones de generación (condicional).
Sin embargo, suelen ser computacionalmente más costosos y lentos en generación.
Conclusión
Los modelos difusivos representan una nueva frontera en la generación artificial de imágenes, fundamentados en procesos matemáticos de difusión y denoising. Con una comprensión clara de su proceso de entrenamiento y arquitectura, cualquier entusiasta puede comenzar a experimentar y construir sus propios modelos desde cero.
Explorando este campo, no solo se obtiene un dominio técnico, sino también una ventana a cómo la IA puede aprender y manipular datos complejos con sorprendente precisión y creatividad.