Introducción a las Redes Neuronales Feedforward: Fundamentos y Ejemplo Práctico para Principiantes
Las redes neuronales feedforward son la piedra angular del aprendizaje profundo y representan una forma simple pero poderosa de construir modelos de Inteligencia Artificial. Son la base para comprender arquitecturas más complejas y se utilizan ampliamente en problemas de clasificación, regresión y reconocimiento de patrones.
En este artículo, abordaremos desde una perspectiva didáctica los conceptos fundamentales de este tipo de red neuronal, su funcionamiento interno y finalmente desarrollaremos un ejemplo práctico con Python para que puedas dar tus primeros pasos en el mundo de la IA.
¿Qué es una Red Neuronal Feedforward?
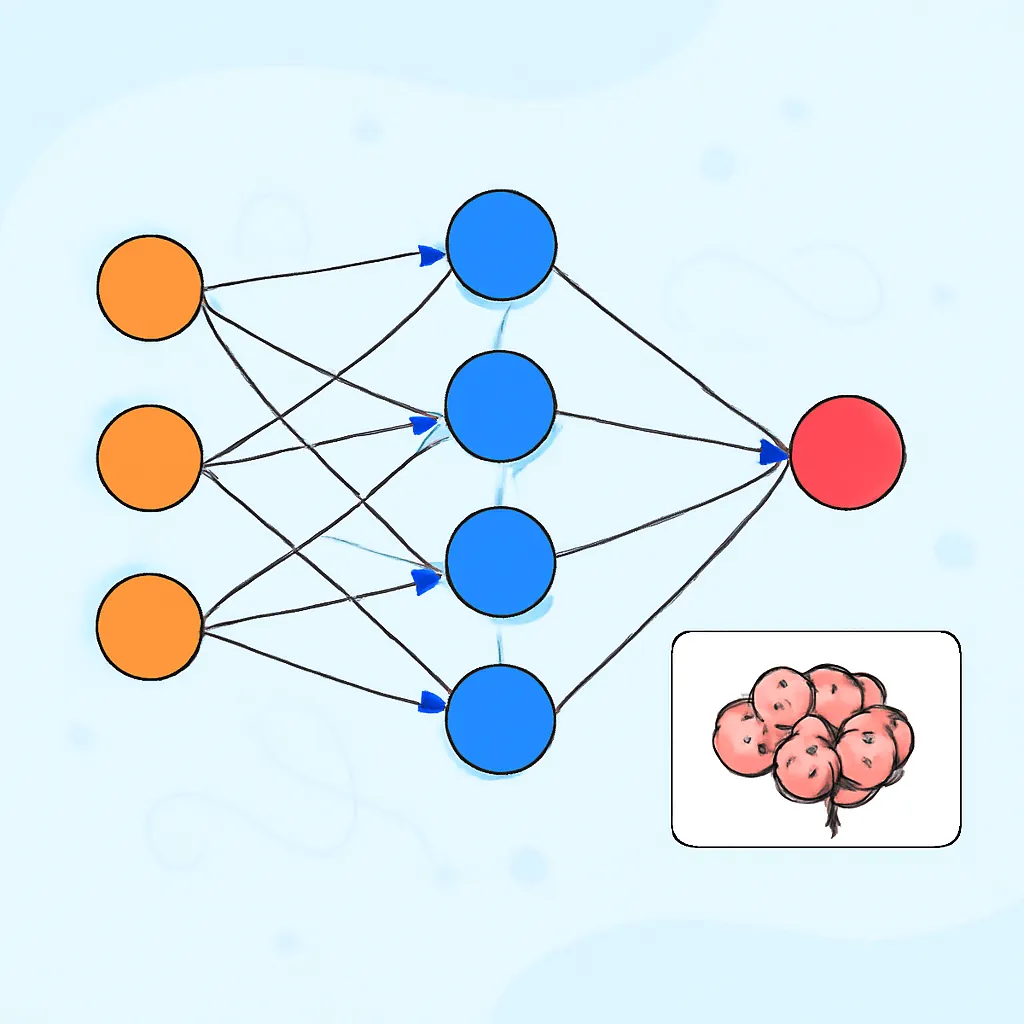
Una red neuronal feedforward es una arquitectura en la que las conexiones entre las neuronas fluyen únicamente hacia adelante, desde la capa de entrada hasta la capa de salida, sin ciclos ni retroalimentación.
Su estructura típica consta de tres tipos de capas:
- Capa de entrada: recibe los datos crudos (por ejemplo, características de un conjunto de datos).
- Capas ocultas: capas intermedias que transforman las entradas mediante potentes funciones matemáticas.
- Capa de salida: genera la predicción o el resultado final del modelo.
El aprendizaje se basa en ajustar los pesos y sesgos de las conexiones para minimizar un error o función de pérdida, generalmente con el algoritmo de retropropagación y optimizadores como gradiente descendente.
Componentes Clave de una Red Feedforward
- Neuronas (Nodos): unidades donde se calcula una suma ponderada de entradas seguida de una función de activación.
- Pesos y Bias (Sesgos): parámetros modificables que ajustan la importancia y el umbral de activación de cada neurona.
- Funciones de Activación: funciones no lineales como ReLU, Sigmoid o Tanh que permiten a la red aprender relaciones complejas.
El flujo de información se produce en sentido único desde la entrada, pasando por las capas ocultas, hasta la salida.
Funcionamiento Básico: Propagación y Aprendizaje
El algoritmo de entrenamiento de una red feedforward consta de dos fases principales:
- Propagación hacia adelante: Se calculan las salidas de cada neurona hasta obtener la predicción final.
- Retropropagación del error: El error entre la predicción y la salida real se propaga hacia atrás para actualizar pesos mediante gradiente descendente.
Este proceso se repite para múltiples iteraciones o épocas, optimizando progresivamente el rendimiento del modelo.
Ejemplo Práctico: Construyendo una Red Feedforward Simple en Python
Veamos un ejemplo sencillo de cómo crear y entrenar una red neuronal feedforward para clasificar puntos en dos clases, usando solo NumPy para entender totalmente el funcionamiento interno.
import numpy as np
# Función de activación Sigmoid y su derivada
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return x * (1 - x)
# Datos de entrenamiento: entradas y salidas (XOR simplificado)
X = np.array([[0,0], [0,1], [1,0], [1,1]])
Y = np.array([[0], [1], [1], [0]])
# Inicialización de pesos y sesgos aleatorios
np.random.seed(1)
input_layer_neurons = X.shape[1] # 2
hidden_layer_neurons = 3
output_neurons = 1
# Pesos
wh = np.random.uniform(size=(input_layer_neurons, hidden_layer_neurons))
bh = np.random.uniform(size=(1, hidden_layer_neurons))
wo = np.random.uniform(size=(hidden_layer_neurons, output_neurons))
bo = np.random.uniform(size=(1, output_neurons))
# Parámetros de entrenamiento
lr = 0.5
epochs = 10000
for i in range(epochs):
# Forward Propagation
hidden_layer_input = np.dot(X, wh) + bh
hidden_layer_activations = sigmoid(hidden_layer_input)
output_layer_input = np.dot(hidden_layer_activations, wo) + bo
predicted_output = sigmoid(output_layer_input)
# Calcular error
error = Y - predicted_output
# Backpropagation
d_predicted_output = error * sigmoid_derivative(predicted_output)
error_hidden_layer = d_predicted_output.dot(wo.T)
d_hidden_layer = error_hidden_layer * sigmoid_derivative(hidden_layer_activations)
# Actualización de pesos y sesgos
wo += hidden_layer_activations.T.dot(d_predicted_output) * lr
bo += np.sum(d_predicted_output, axis=0, keepdims=True) * lr
wh += X.T.dot(d_hidden_layer) * lr
bh += np.sum(d_hidden_layer, axis=0, keepdims=True) * lr
# Resultado final
print("Salida final después del entrenamiento:")
print(predicted_output.round())
Este pequeño script implementa toda la lógica de una red feedforward desde cero: inicializa pesos, propaga datos, calcula errores y ajusta parámetros para aprender el patrón XOR, famoso por ser no lineal.
Conclusión
Las redes neuronales feedforward son el punto de partida ideal para comprender cómo las máquinas pueden aprender de datos mediante ajuste iterativo de parámetros. Este artículo ha presentado una explicación clara sobre su estructura, componentes y proceso de aprendizaje, complementado con un ejemplo práctico accesible para principiantes.
Dominar este tipo de redes es esencial para avanzar luego hacia arquitecturas más sofisticadas y proyectos reales de inteligencia artificial. Te invitamos a modificar el código y experimentar con distintos parámetros para consolidar tus conocimientos en IA.