Introducción a las Redes Neuronales Recurrentes (RNN): Fundamentos y Aplicaciones para Principiantes
Las Redes Neuronales Recurrentes (RNN) son uno de los pilares fundamentales en el procesamiento de datos secuenciales y temporales en Inteligencia Artificial. A diferencia de las redes neuronales tradicionales, las RNN están diseñadas para manejar información que depende del orden y tiempo, por lo que son ideales para tareas como procesamiento de lenguaje natural, reconocimiento de voz y series temporales.
En este artículo, explicaremos de manera clara y sencilla cómo funcionan estas redes, sus principales características y aplicaciones, además de mostrar un pequeño ejemplo práctico para entender su estructura básica.
¿Qué son las Redes Neuronales Recurrentes?
Una RNN es un tipo especial de red neuronal que puede procesar secuencias de datos, pues tiene la capacidad de mantener una especie de memoria interna sobre información previa mediante bucles en su arquitectura. Esto permite que la red recuerde el contexto de entradas anteriores y utilice esta información para influir en la salida actual.
Mientras que una red neuronal clásica procesa las entradas de manera independiente, las RNN manejan datos en serie, haciendo que la salida dependa tanto de la entrada actual como del estado previo de la red.
Arquitectura básica de una RNN
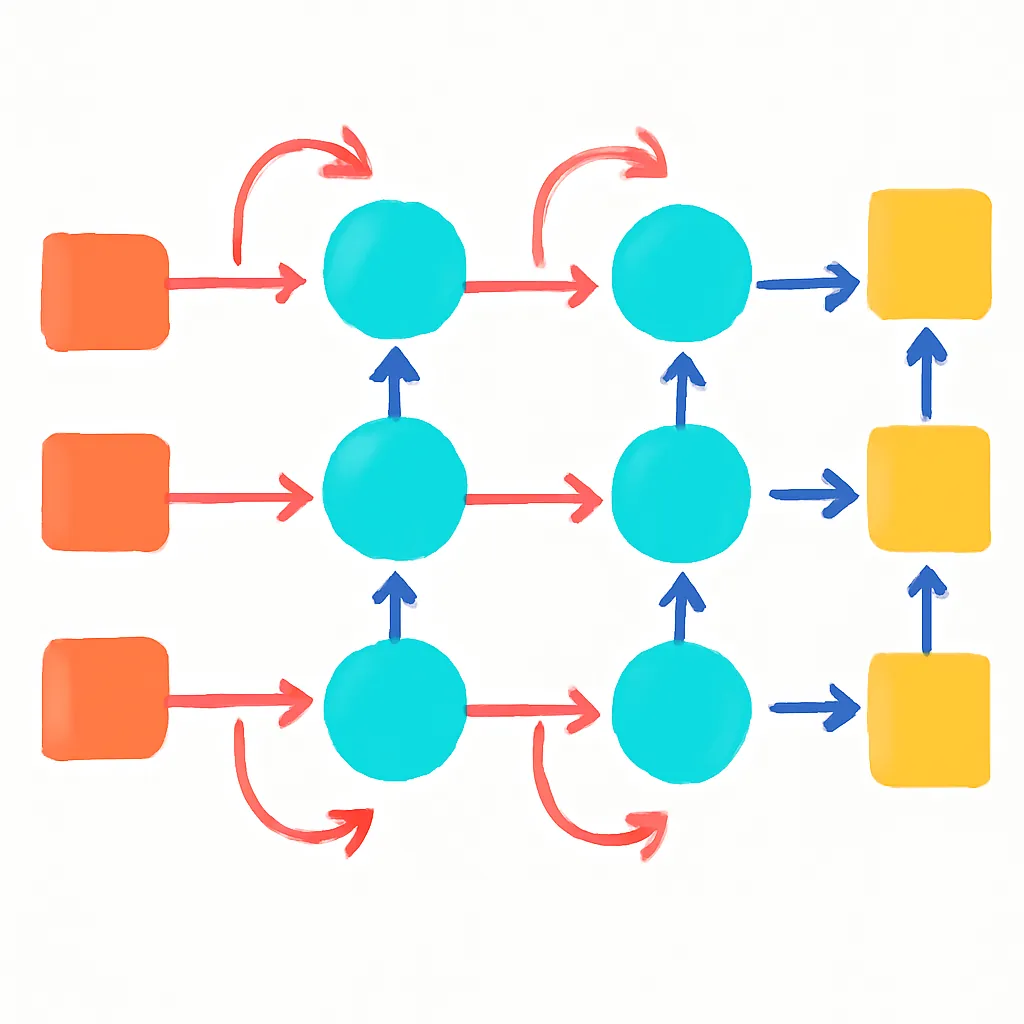
El núcleo de una RNN es sencillo pero poderoso. Cada unidad de tiempo recibe un vector de entrada, procesa esta información junto con el estado oculto de la etapa anterior y genera una salida y un nuevo estado oculto.
 Esquema de una RNN (desenrollada en el tiempo). Fuente: Wikipedia
Esquema de una RNN (desenrollada en el tiempo). Fuente: Wikipedia
Formalmente, para cada instante de tiempo t se calcula el estado oculto ht y la salida yt según:
- ht = f(Wihxt + Whhht-1 + bh) donde f es una función no lineal (típicamente tanh o ReLU).
- yt = g(Whoht + bo) con g dependiendo del problema (softmax para clasificación, por ejemplo).
¿Para qué se usan las RNN?
Las RNN son especialmente útiles para datos secuenciales o temporales como:
- Procesamiento de lenguaje natural (NLP): traducción automática, generación de texto, reconocimiento de voz.
- Predicción de series temporales: análisis financiero, climatología, datos de sensores IoT.
- Análisis de secuencias biológicas: secuencias de ADN, proteínas.
- Reconocimiento de patrones temporales: análisis de video o audio en tiempo real.
Ejemplo básico: Implementación de una RNN simple en Python con PyTorch
A continuación, presentamos un ejemplo sencillo que ilustra cómo crear una RNN básica para procesar secuencias:
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x tiene dimensión (batch_size, seq_length, input_size)
h0 = torch.zeros(1, x.size(0), self.hidden_size) # estado inicial oculto
out, hn = self.rnn(x, h0)
# out tiene dimensión (batch_size, seq_length, hidden_size)
out = self.fc(out[:, -1, :]) # tomamos la salida del último paso de tiempo
return out
# Parámetros
input_size = 5 # por ejemplo, características por paso de tiempo
hidden_size = 10
output_size = 1 # ejemplo de regresión
seq_length = 7
batch_size = 3
# Datos aleatorios de ejemplo
x = torch.randn(batch_size, seq_length, input_size)
# Crear modelo y hacer forward
model = SimpleRNN(input_size, hidden_size, output_size)
output = model(x)
print(output)
Este código define una RNN que procesa secuencias de longitud 7 con 5 características cada paso y produce una predicción por secuencia. La red utiliza un estado oculto de tamaño 10.
Limitaciones y evolución: LSTM y GRU
Aunque las RNN estándar son potentes, presentan limitaciones importantes como el problema del desvanecimiento y explosión del gradiente que dificulta aprender dependencias a largo plazo en las secuencias.
Para superar esto, se desarrollaron las arquitecturas LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Unit), que introducen mecanismos de puerta para controlar el flujo de información y mejorar el aprendizaje a largo plazo.
Estas variantes son las más utilizadas en la práctica, pero entender la RNN básica es fundamental para dominar su funcionamiento y la lógica detrás de las redes recurrentes.
Conclusión
Las Redes Neuronales Recurrentes son una herramienta imprescindible para tratar datos secuenciales en IA. Su capacidad para retener información temporal y utilizar el contexto previo las hace ideales para tareas donde el orden y la evolución de datos son esenciales. Aunque presentan desafíos técnicos, su comprensión es clave para profundizar en arquitecturas avanzadas y aplicaciones actuales del aprendizaje automático.
Hemos cubierto sus principios fundamentales, arquitectura básica y aplicaciones junto con un ejemplo práctico para facilitar el entendimiento de esta poderosa técnica.